
Gesture Controlled Robot via TensorFlow Object Detection and OpenCV
Astract/Intro:
Ever wanted to control a robot via hand gestures? You’ve come to the right place! This project is an implementation of a hand gesture controlled robot. This project was completed by Nathan Faber and Sander Miller, for the course Computational Robotics @Olin College of Engineering.
We chose this project in order to further explore algorithms related to computer vision and was scoped to allow us to learn about multiple parts of computer vision processing. Our plan was to utilize a deep-learning object detection model to localize the hand within an image and then use color thresholding and a variety of image processing techniques to determine how many fingers are showing. This data would then be used to change/control the neato’s movement.
Goal of project
This project seeks to show a working implementation of the above methods/techniques such that others can understand our process and so we can gain understanding about how these types of problems are tackled in industry.
Overview / an example of it in action!
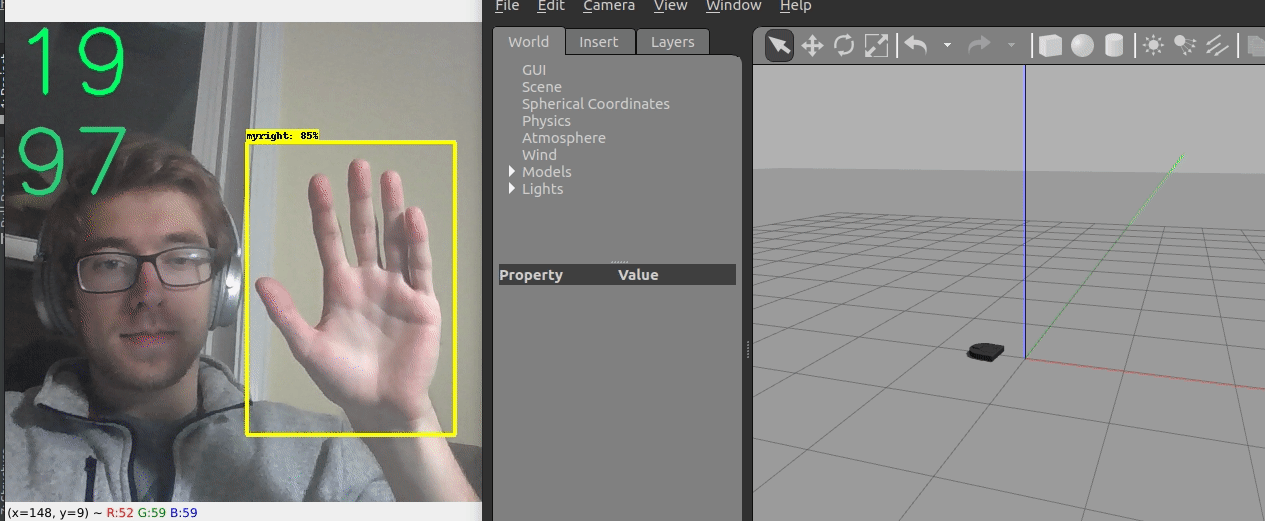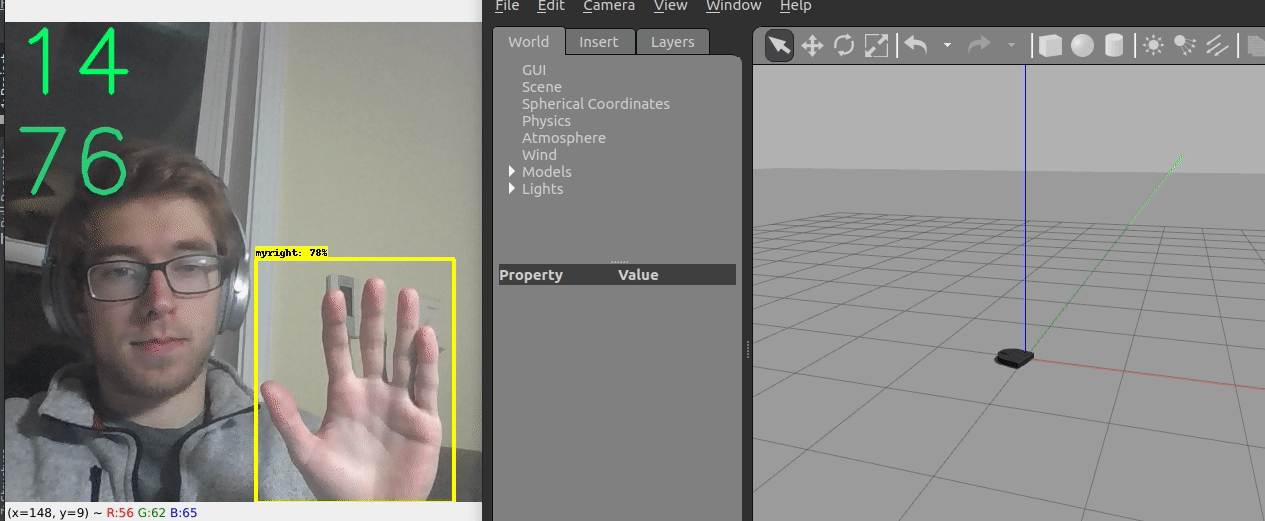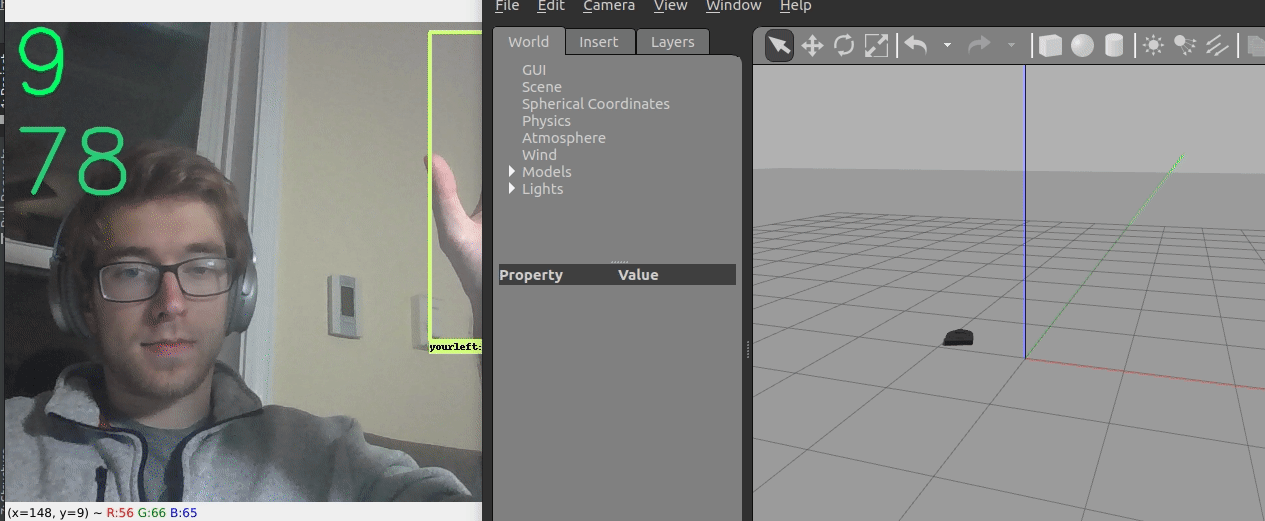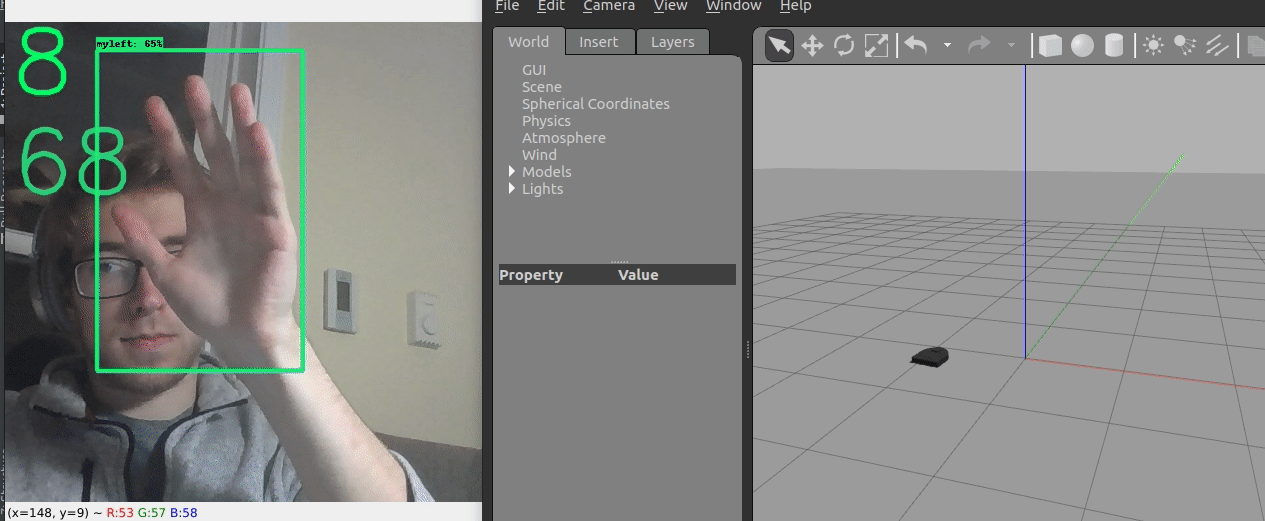
We ended up creating two different control frameworks.

The first shown above uses the location of the hand within the image to control the robot. The y coordinate controls the linear velocity, while the x coordinate controls the angular velocity.
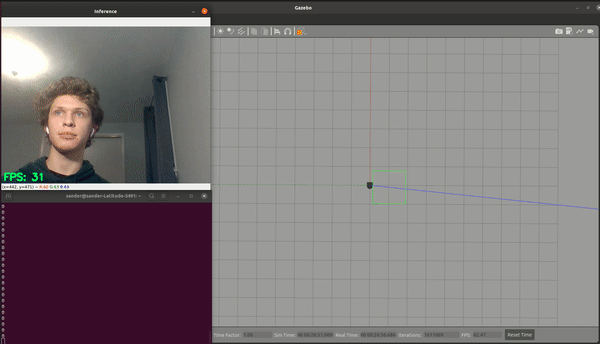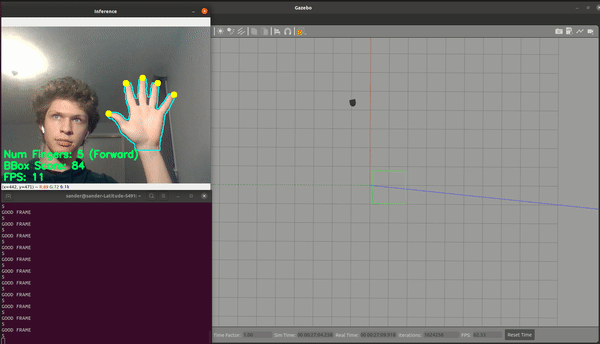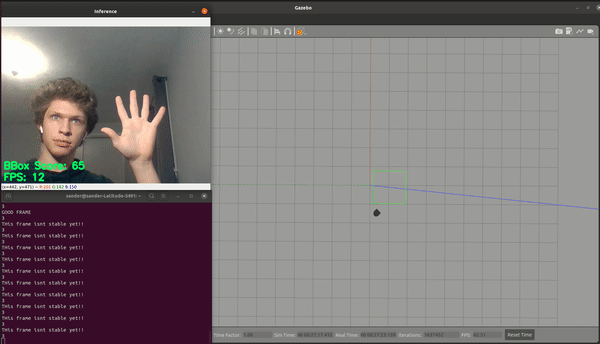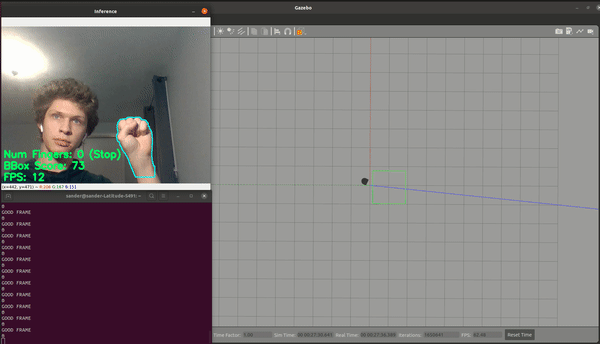
| Num Fingers | Command |
|---|---|
| 0 | Stop |
| 2 | Turn Left |
| 3 | Turn Right |
| 4 | Reverse |
| 5 | Forward |
Machine Learning Model Development Process
Developing the ML object detection model can be broken down into multiple steps. For even more detail of the process to create this model please look at our other documentation
Preliminary Decisions
- We chose to use the Tensorflow Object Detection API. This was chosen because of our prior experience with it.
- Inputs would be webcam data in real time
- Interested in hand orientation/pose
Research/Experimental Phase
The original plan was to train our own Model to detect different hand poses based on data we created. For this to be feasible we could only label a dataset for full frame detection (adding bounding boxes to images is extremely labor intensive). This was tested at a very small scale with roughly 50 or so images in 3 different labels. The results were not at all promising, however that was likely because the model had very little training data and we were not utilizing a transfer learning approach. It also became evident that we were not interested in pouring tons of time into making a dataset as opposed to exploring more computer vision processes.
This led to a pivot to an object detection model. We were very interested in the repo here: github.com/victordibia/handtracking We planned to port this code over to the upgraded/new TF2 object detection API. This project also made use of a labeled dataset: Egohands
This dataset and paper gave us confidence that we could train a model that would recognize hands and allow us to generate a bounding box around them. This bounding box will then be cropped and passed on to more image processing to determine the pose/shape of the hand
Development Phase (Object Detection)
This process can be broken down into several different steps.
Obtaining Training Data
- The above Egohands dataset is publicly available. TIt contains a set of all the images and annotations. These annotations are bounding box level annotations and split into 4 different classes.
Converting Training Data/labels
- The annotations are saved into a format that can’t be read by the tensorflow dataset creators.
- Modifying scripts from github.com/victordibia/handtracking took the processing from .m files to .xml to .csv which can be read by tensorflow scripts.
- The images and .csv files are converted together in to TFRecords (.record). There is a train.record and test.record to reflect the training and validation image sets. TFRecords are the final format used in training.
Choosing a Model for Transfer Learning
- Tensorflow has a model zoo containing models that are suitable to fine tune for object detection tasks.
- We had experience with mobilenetv2, and thought that the 320x320 size would be sufficient for our webcam and would be trainable on our hardware (GTX 1060 6gb)
- We also trained a model on EfficientNet 320x320. This model showed similar accuracy results, but took much longer to train and was too slow at performing inference to be effective in real time on a CPU-only machine (one of our requirements)
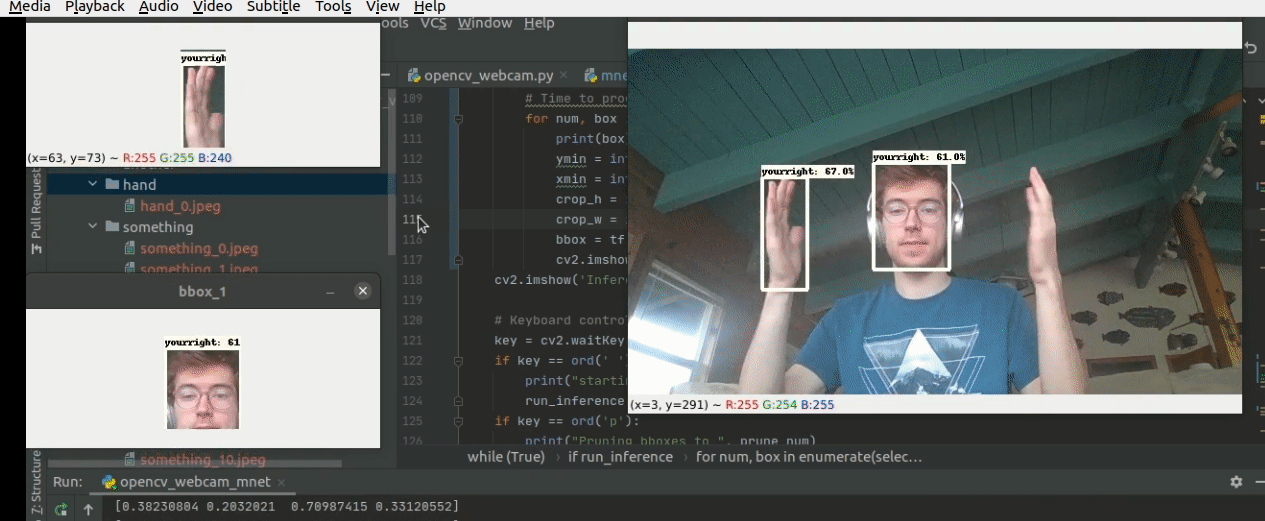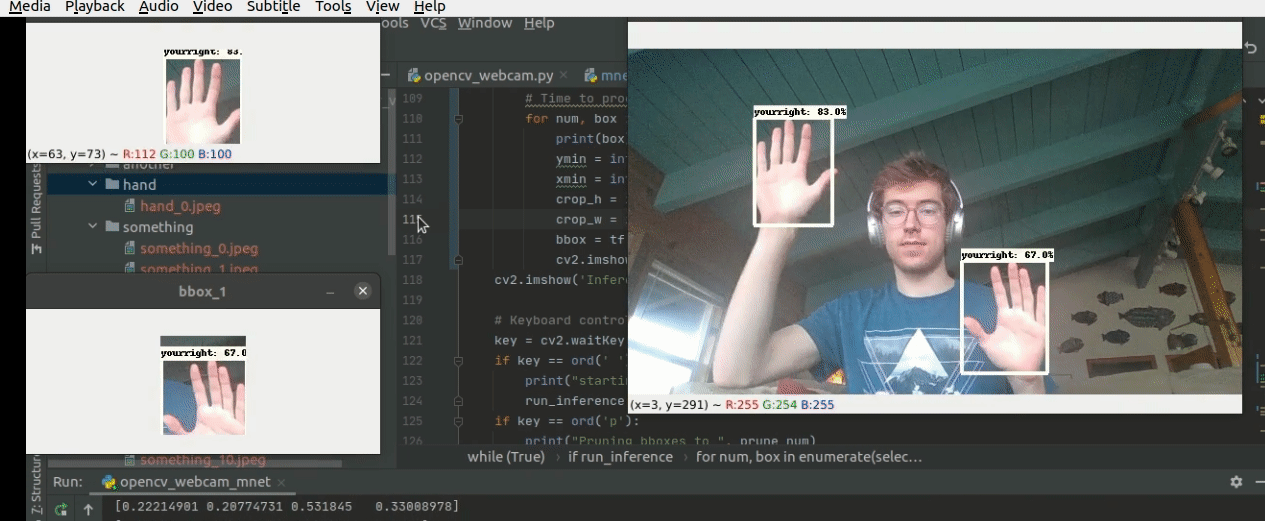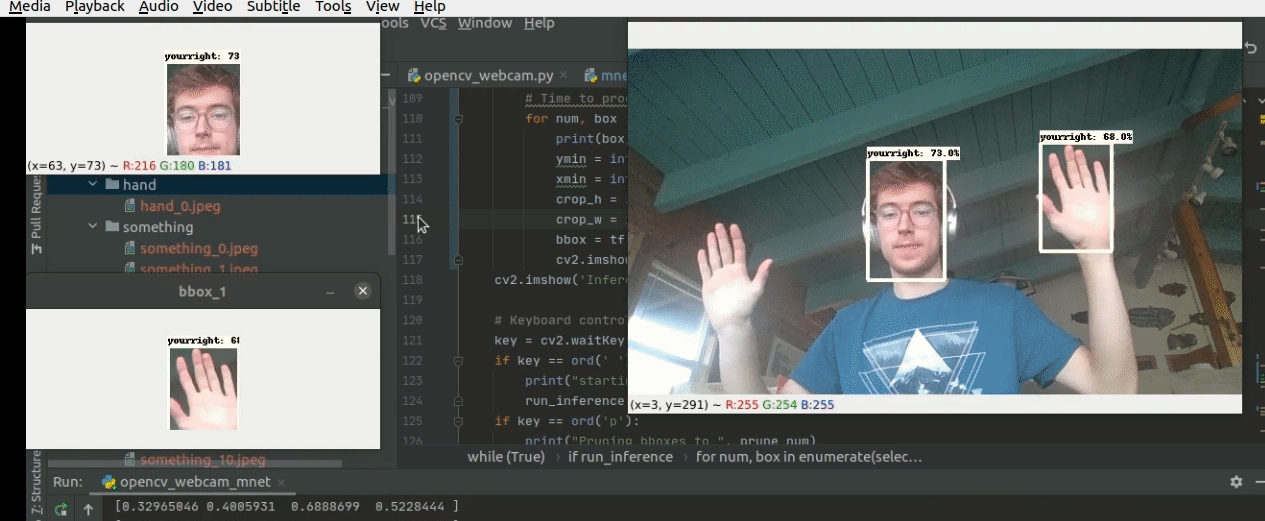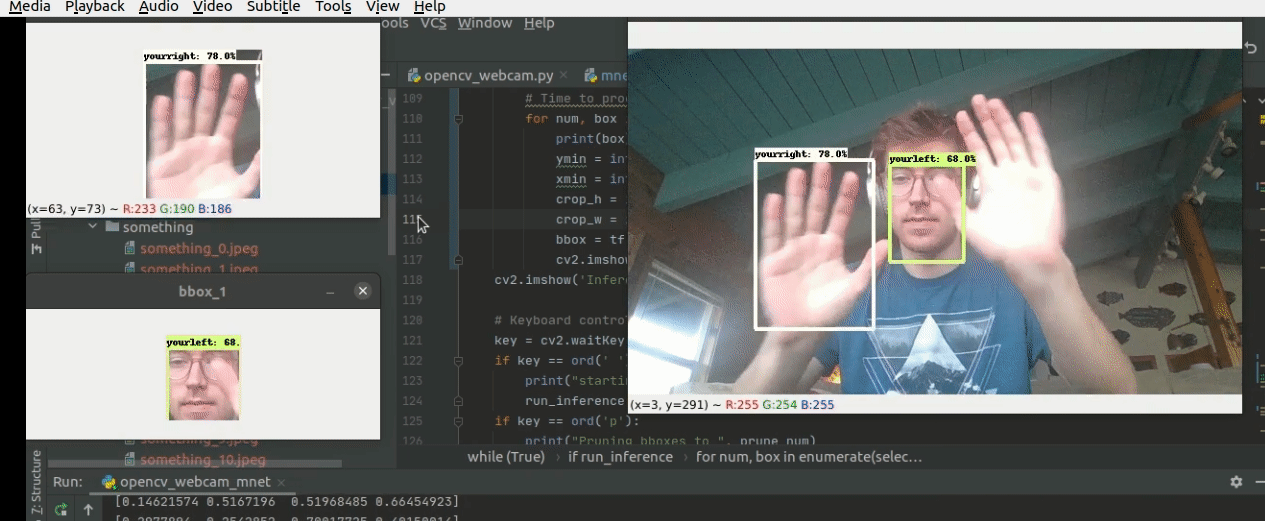
The model at work!
Here is the first run of the Mobilenetv2 320x320 custom model
center>
OpenCV Implementation and Finger Counting
Hand Segmentation/Masking
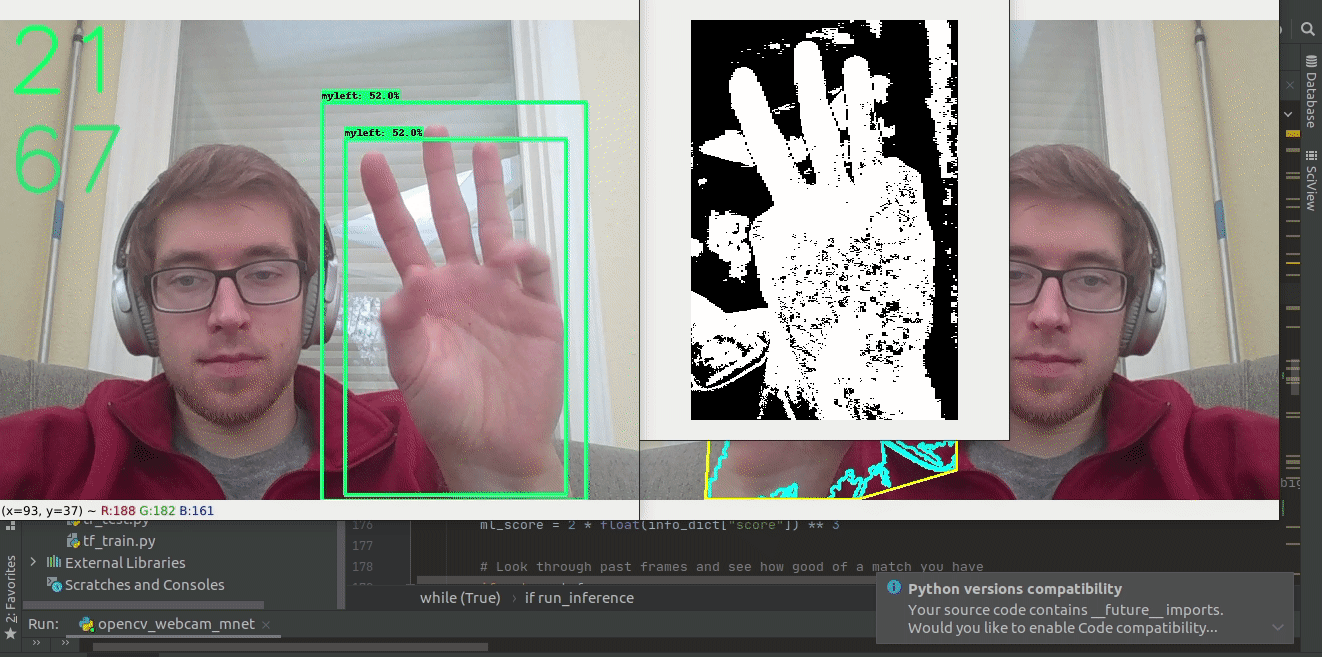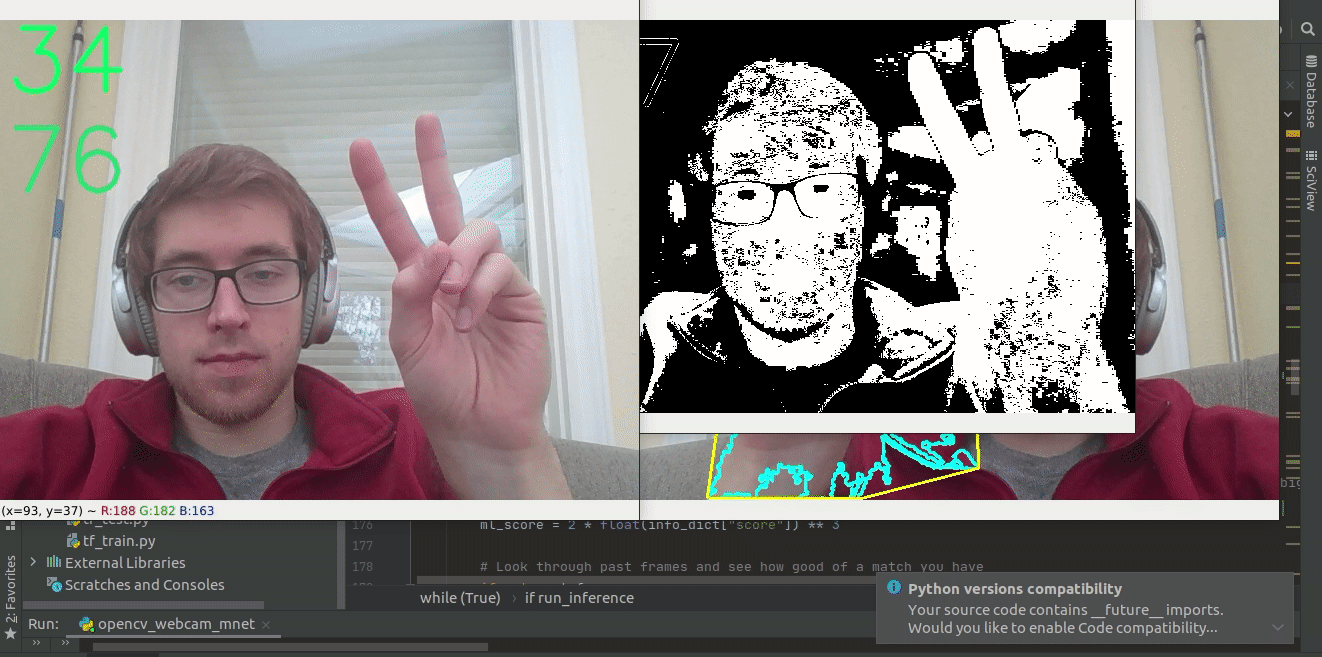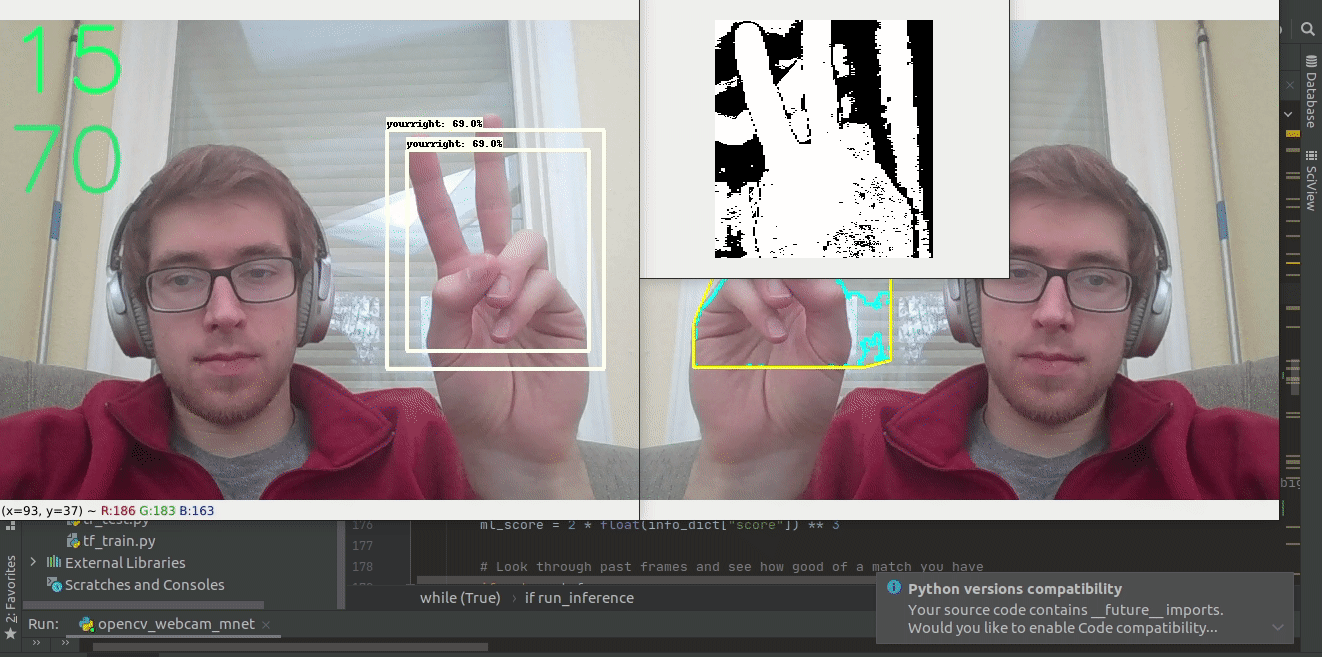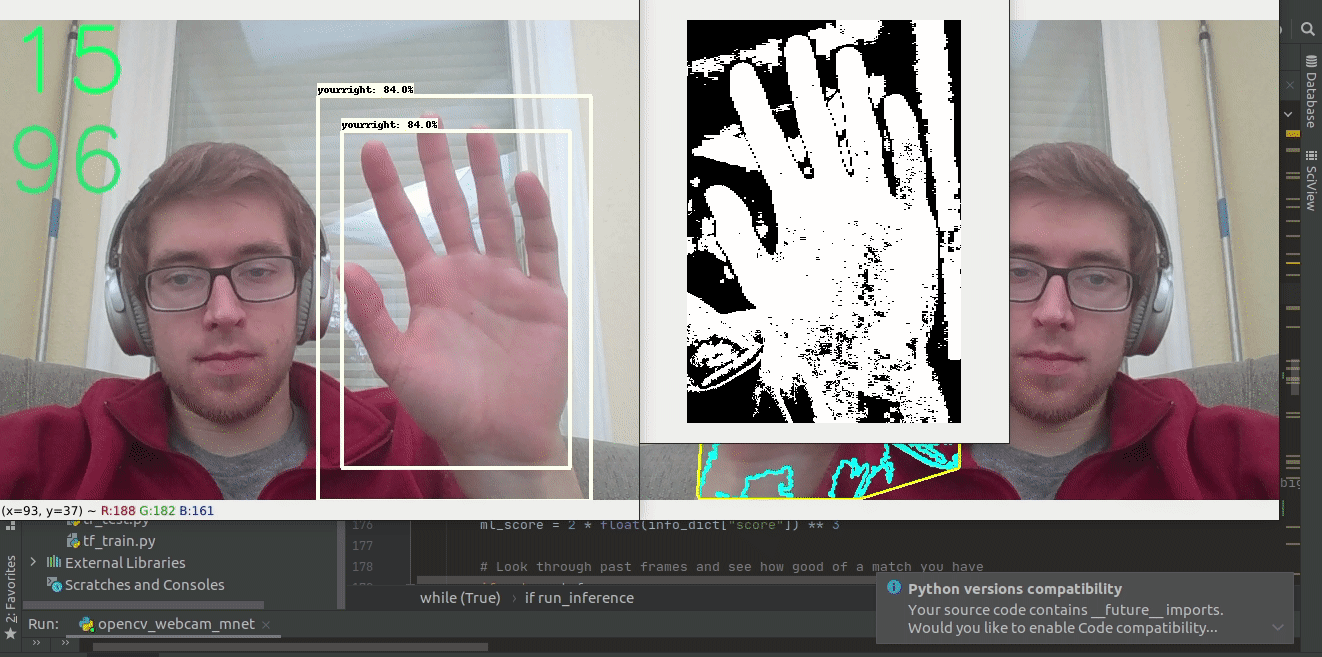
After the hand has been localized within the image using our TensorFlow model, we use pixel-wise segmentation to isolate the hand from background pixels within the bounding box. We accomplished this through color thresholding, using parameters described by N. Dwina et al. These parameters are listed below in the RGB color space.

We initially tried to loop through each pixel of each frame but that was very slow, giving us very few frames per second. In order to speed up the thresholding process we did the thresholding in layers. A new layer was created for each parameter above. Pixels that fulfilled the constraint were given a value of 255, while pixels that did not meet the criteria were given a value a zero. Then, all 8 layers were added together and normalized to a scale between 0 and 8 based on the number of thresholds each pixel met. Any pixel that met all 8 criteria was given a value of 255, while everything else was set to 0. This strategy proved much more computationally efficient. Finally, we made use of OpenCV’s erode() and dilate() functions to clean some of the noise in our newly created binary mask.

Contours, Convex Hulls and Defects

The three tools we need in order to be able to identify and count the number of fingers being held up are contours, convex hulls, and convexity defects.
Once the binary mask has been created we can use OpenCV’s findContours() function to create a contour outlining the pixels belonging to the hand. After creating the contour, we used OpenCV’s convexHull() function to create a convex polygon consisting of the outermost edges of the contour. Next, we used OpenCV’s convexityDefects() function to identify major concavities within the convex hull.
Identifying and Counting Fingers
By using convexity defects we are able to identify fingers. A convexity defect is made up of three points, the starting point, located on the convex hull, the deepest point in the cavity, furthest from the convex hull, and the ending point again located on the convex hull, but on the other side of the cavity.

ROS Node and other Integration
Model Output processing
The model along with the webcam processing causes the software to run <20fps while running the neato simulator. We feel this is a reasonable rate for our purposes. This rate is still fast enough that there is a large chance of bad annotations being made during transition movements (our model isn’t perfect and it’s making 20 predictions a second) because of this we decided to attempt to smooth the resulting bounding boxes. This would allow us to save computation time and only perform finger detection on frames that are likely to be valid.
Smoothing is accomplished by:
- Recording past bounding boxes
- calculating a “score” for each new bounding box. This is calculated as follows:
area = area of bounding box / .45
ml_score = 2 * float(current prediction confidence) ** 3
x_off = abs(center x differences)
y_off = abs(center y differences)
x_score = 1/math.e**(x_off**(1/3))
y_score = 1/math.e**(y_off**(1/3))
frame_score = x_score+y_score+area_score+ml_score # Max should be around 5
- The above implementation has not been mathematically justified. It attempts to give high scores to boxes that are close in location to previous boxes and to ones with high confidence and size
- If the “score” is significantly lower than the average score of the stored boxes then this is likely a bad frame aka (low confidence, small bbox, or large translation)
Finger/Neato Post-Processing
There is also post processing done on the neato side of things to help ensure continuity of commands being sent to the robot.
Once the bounding box has been read and the hand pose has been determined the neato waits for multiple of the same signal before doing anything. Our current implementation allows a finger count/gesture to be acted upon if it is in 7 of the last 10 frames.
- This added redundancy helps to alleviate very sporadic/jumpy behavior
- This comes at a price of reaction time as it will take longer(ie more processed frames) for a given action/hand pose to enact a change and stop
- On a higher power system there would be less slowdown (higher frame rate) and it would likely perform better
Final Results
Our final implementation sports 2 different control styles. One style simply uses the location of a hand in the frame to control the linear and angular velocity of the neato. This is quite fun to control and is fairly intuitive.
Our intended control method uses the number of fingers showing to start different behaviours. This is much harder to implement and depends significantly on the quality of the bounding box made by the object detection model, as well as the environmental lighting’s effects on color thresholding. While this may seem like a less complicated control method than the above control style it is significantly more complicated. Also keep in mind that the position of the hand in the frame is still being calculated. It would be trivial to have certain numbers of fingers do different things in different parts of the frame!
Notable Challenges/Roadblocks
As expected, this project had its fair share of difficulties. These are summarised below:
- TensorFlow 2 object detection installation across multiple systems was finicky. Graphics drivers were even more of a mess
- Lighting for ML object detection model changes how well it is able to predict. This task would likely have benefit from creating a small amount of our own training data
- Lighting also proved troublesome for segmentation of the hand. Small changes in light would lead to vast changes in the deteced hand shape.
- Bounding boxes are all different sizes and there are a large amount of “noisy” predictions. (Our smoothing efforts work to alleviate some of this)
- Bounding boxes often chop off fingers (We increase the box size by 10% on all detections in each direction). This helps make sure that we have the full hand to look for fingers in. See the below gif where there is an incrased bounding box.
- Unfortunately OpenCV doesn’t have simple ways of playing back recorded video at recorded speed. It is more geared towards processing through frames. This meant that we had to test things in real time which led to inconsistent/reproducible tests, and a larger amount of time.
Future Iterations/Improvements
In almost any views, this is a very rudimentary start to the problem of “gesture” or “hand” control. However, our experimentation led us to understand more of the problem and how it may be more accurately addressed. To improve upon our work we feel that the following ideas show promise or are worth exploring:
- A single Machine learning model to get hand pose detection (https://ai.googleblog.com/2019/08/on-device-real-time-hand-tracking-with.html). This would simplify the process to potentially be less affected by lighting conditions.
- Adjust for lighting and contrast to improve model and masking
- Use a segmenting machine learning model rather than object detection and homebrewed masking. This would improve speed and likely quality
- Supplement training data with data specific to the task. In our case making a few frames of our hands in the orientations we were interested in would likely really help our object detection model.
- Use an ML model to determine appropriate masking parameters for hand colors
- Experiment with training a full frame image classifier. Implementation would be simple and it could potentially provide simple gesture indication without the location and size parts that are gained from doing object detection. This would also eliminate other processing needed to determine hand gesture after localizing it with our current model.
Key Takeaways/Conclusion
- Acquiring data is likely the hardest and most time consuming task of most, if not all, ML projects
- Computations are only as good as the data cleaning/processing on the input data. In our case, having good bounding boxes dictates if the rest of our process works well
- Specing out various functions and having a code outline or structure can help make the project much clearer and easy to understand. We lacked a clear outline during development and time was wasted scrolling around poorly abstracted code.
Sources
Indiana University, EgoHands: A Dataset for Hands in Complex Egocentric Interactions vision.soic.indiana.edu/projects/egohands/
Mühler, Vincent. “Simple Hand Gesture Recognition Using OpenCV and JavaScript.” Medium, Medium, 7 Dec. 2017, medium.com/@muehler.v/simple-hand-gesture-recognition-using-opencv-and-javascript-eb3d6ced28a0.
N. Dwina, F. Arnia and K. Munadi, “Skin segmentation based on improved thresholding method,” 2018 International ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI-NCON), Chiang Rai, 2018, pp. 95-99, doi: 10.1109/ECTI-NCON.2018.8378289.
Victor Dibia, HandTrack: A Library For Prototyping Real-time Hand TrackingInterfaces using Convolutional Neural Networks, https://github.com/victordibia/handtracking